- Course overview
- Search within this course
- Network analysis in biology
- Introduction to graph theory
- Types of biological networks
- The sources of data underlying biological networks
- Protein-protein interaction networks
- Summary
- Quiz: Check your learning
- Your feedback
- Learn more
- References
![]()
All materials are free cultural works licensed under a Creative Commons Attribution 4.0 International (CC BY 4.0) license, except where further licensing details are provided.
Sources of PPI data
The first step in performing PPIN analysis is, of course, to build a network. There are different sources of PPI data (Figure 24) that can be used to do this and it is important to be aware of their advantages and disadvantages.
Essentially, you can obtain PPI data from:
- Your own experimental work, where you can choose how the data is represented and stored
- A primary PPI database. These databases extract PPIs from the experimental evidence reported in the literature using a manual curation process. They are the primary providers of PPI data and they can represent a great deal of detail about interactions, depending on the database
- A metadatabase or a predictive database. These resources bring together the information provided by different primary databases and provide a unified representation of the data to the user. Predictive databases go beyond that and use the experimentally produced datasets to computationally predict interactions in unexplored areas of the interactome. Predictive databases provide a way of broadening or refining the space of experimentally derived interactions, but the datasets produced are noisier than those from other sources
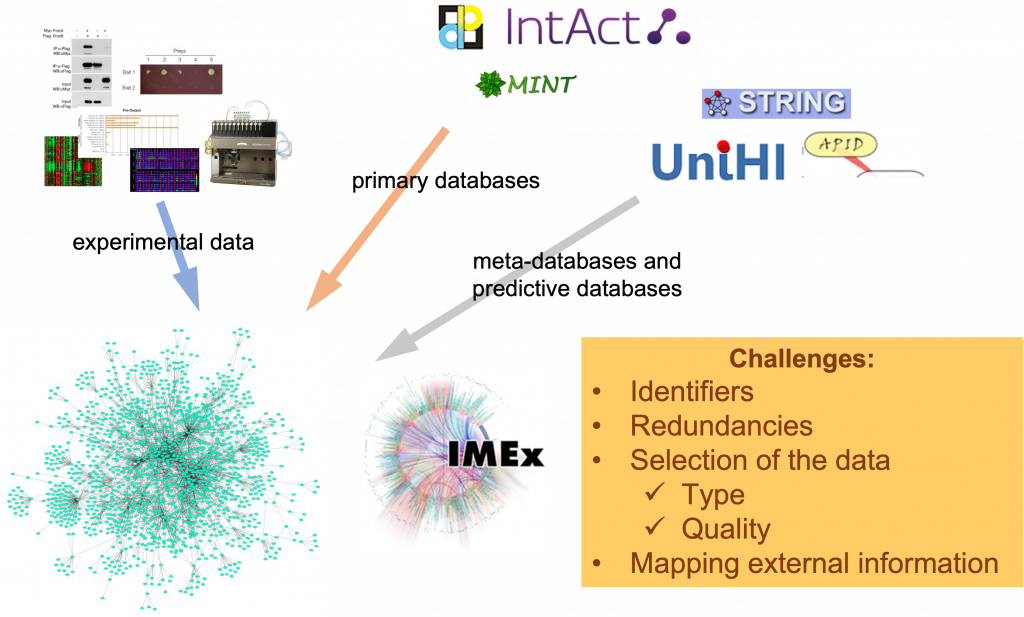
It will often be necessary to integrate PPI data from multiple sources as no database has a full representation of all the PPI evidence available. This creates some interesting challenges because different databases use different identifiers and contain different types of data.
In order to avoid redundancies and inconsistencies, it is important to understand the differences between the different databases in terms of:
- The type of data and metadata they include. For example, some databases will give you only experimentally-derived data and others will also include predictions. Similarly, the level of detail given about the experimental setup varies between databases
- The identifiers used by the database. Different databases make different choices in this regard, so sometimes you may have to map different types of identifiers for data integration